想要在搜索引擎中有好的排名表现,网站的收录是基础,从另一方面讲,页面收录的数量级别也代表着网站的整体质量。我认为想让百度网站收录你得先要了解搜索引擎的工作原理,这样才可以有针对性的去迎合搜索规则,让网站收录达到理想状态。
搜索引擎的工作原理非常复杂,接下来的简单讲一下搜索引擎怎么收录并实现网页排名的。
搜索引擎的工作过程大体上可以分成三个阶段:
1、爬行和抓取:搜索引擎蜘蛛通过跟踪链接发现和访问网页,读取页面HTML代码,存入数据库。
2、预处理:索引程序对抓取来的页面数据进行文字提取、中文分词、索引、倒排索引等处理,以备排名程序调用。
3、排名:用户输入查询词后,排名程序调用索引库数据,计算相关性,然后按一定格式生成搜索结果页面。
一、爬行和抓取
1) 蜘蛛访问。相信大家都知道它了,蜘蛛访问任何一个网站时,都会先访问网站根目录下的robots.txt文件,如果robots.txt文件禁止搜索引擎抓取某些文件和目录,蜘蛛会遵守协议,不抓取被禁止的网址。
2) 跟踪链接。为了抓取网上尽量多的页面, 搜索引擎蜘蛛跟踪页面上的链接,从一个页面爬到下一个页面,最简单的爬行策略分为两种:一种是深度优先,另一种是广度优先。
深度是指蜘蛛沿着发现的链接一直向前爬行,直到前面再也没有其他链接,然后返回到第一个页面,沿着另一个链接再一直往前爬行。
广度是指蜘蛛在一个页面上发现多个链接时,不是顺着一个链接一直向前,而是把页面上所有第一层链接都爬一遍,然后再沿着第二层页面上发现的链接爬向第三层页面。
3) 吸引蜘蛛。SEO人员想要百度网站收录,就要想办法吸引蜘蛛来抓取,蜘蛛只会抓取有价值的页面,以下是五个影响因素:网站和页面权重、页面更新度、导入链接、与首页的距离、URL结构。
4) 地址库。为了避免重复爬行和抓取网址,搜索引擎会建立一个地址库,记录已经被发现但还没有抓取的页面,以及已经被抓取的页面。蜘蛛在页面上发现链接后并不是马上就去访问,而是将URL存入地址库,然后统一安排抓取。
地址库中URL有几个来源:
① 人工录入的种子网站;
② 蜘蛛抓取页面后,从HTML中解析出新的链接URL,与地址库中的数据进行对比,如果是地址库中没有网址,就存入待访问地址库;
③ 站长通过接口提交进来的网址;
④ 站长通过XML网站地图、站长平台提交的网址;
5) 文件存储。搜索引擎蜘蛛抓取的数据存入原始页面数据库。
6) 爬行时进行复制内容检测。
二、预处理
在一些SEO经验分享中,“预处理”也被简称为“索引”,因为索引是预处理最主要的内容:
1、提取文字
我们存入原始页面数据库中的是HTML代码,而HTML代码中,不仅有用户在页面上直接可以看到的文字内容,还有其他例如JS,AJAX等这类搜索引擎无法用于排名的内容。首先要做的,就是从HTML文件中去除这些无法解析的内容,提取出可以进行排名处理步骤的文字内容。
2、中文分词
分词是中文搜索引擎特有的步骤,搜索引擎存储/处理页面/用户搜索时都是以词为基础的。方法基本分两种:一种基于词典匹配,另一种是基于统计。
3、去停止词
不管是英文还是中文,页面中都会有一些出现频率很高的,对内容没有任何影响的词,如:的、啊、哈之类,这些词被称为停止词。搜索引擎会去掉这些停止词,使数据主题更突出,减少无谓的计算量。
4、去噪声词
大部分页面里有这么一部分内容对页面主题没什么贡献,比如A页面的内容是一篇关于百度网站收录的文章,关键词是百度网站收录,但是除了讲解网站收录这个内容的主体内容外,共同组成这个页面的还有例如页眉,页脚,广告等区域。
这些部分出现的词语可能和页面内容本身的关键词并不相关,搜索引擎的排名程序在对数据进行排名时不能参考这些噪声内容,在预处理阶段就需要把这些噪声时别出来并消除它们。消除噪声的方法是根据HTML的标签对页面进行分块,如页眉是header标签,页脚是footer标签等等,去除掉这些区域后,剩下的才是页面主体内容。
5、内容去重
也就是去掉重复的网页,同一篇文章经常会重复在不同网站/同一个网站的不同网址上。为了用户的体验,去重步骤是必须的,搜索引擎会对页面进行识别与删除重复内容,这个过程称为内容去重,也是影响百度网站收录的点之一。
6、正向索引
可以简称为索引,经过上述各步骤(提取、分词、消噪、去重)后,搜索引擎最终得到的就是独特的、能反映页面主体内容的、以词为单位的内容。
接下来由搜索引擎的索引程序提取关键词,按照分词程序划分好的词,把页面转换为一个由关键词组成的集合,同时还需要记录每一个关键词在页面上的出现频率、出现次数、格式(如是出现在标题标签、黑体、h标签、还是锚文字等)、位置(如页面第一段文字等)。搜索引擎的索引程序会将页面和关键词形成的词表结构存储进索引库。
7、倒排索引
正向索引不能直接用于排名,假设用户搜索关键词【2】,如果只存在正向索引,排名程序需要扫描所有索引库中的文件,找出包含关键词【2】的文件,再进行相关性计算。
这样的计算量无法满足实时返回排名结果的要求,搜索引擎会提前对所有关键词进行分类,将正向索引数据库重新构造为倒排索引,把文件对应到关键词的映射转换为关键词到文件的映射,在倒排索引中关键词是主键,每个关键词都对应着一系列文件,比如下图第一排右侧显示出来的文件,都是包含了关键词1的文件。这样当用户搜索某个关键词时,排序程序在倒排索引中定位到这个关键词,就可以马上找出所有包含这个关键词的文件。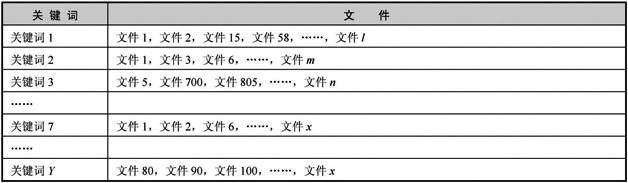
三、搜索结果排名
经过前面的蜘蛛抓取页面,对数据预处理和索引程序计算得到倒排索引后,搜索引擎就准备好可以随时处理用户搜索了。用户在搜索框输入想要查询的内容后,排名程序调用索引库的数据,计算排名后将内容展示在搜索结果页中。
1、搜索词处理
搜索引擎接收到用户输入的搜索词后,需要对搜索词做一些处理,然后才进入排名过程。搜索词处理过程包括:中文分词、去停止词、指令处理。
完成上面的步骤后,搜索引擎对剩下的内容的默认处理方式是在关键词之间使用“与”逻辑。
比如用户在搜索框中输入“减肥的方法”,经过分词和去停止词后,剩下的关键词为“减肥”、“方法”,搜索引擎排序时默认认为,用户想要查询的内容既包含“减肥”,也包含“方法”。
2、文件匹配
搜索词经过上面的处理后,搜索引擎得到的是以词为单位的关键词集合。进入的下一个阶段:文件匹配阶段,就是找出含有所有关键词的文件。在索引部分提到的倒排索引使得文件匹配能够快速完成,假设用户搜索“关键词1 关键词2”,排名程序只要在倒排索引中找到“关键词1”和“关键词2”这两个词,就能找到分别含有这两个词的所有页面文件。
3、初始子集的选择
找到包含所有关键词的匹配文件后,还不能对这些文件进行相关性计算,因为在实际情况中,找到的文件经常会有几十、几百万,甚至上千万个。要对这么多文件实时进行相关性计算,需要的时间还是挺长的。百度搜索引擎,最多只会返回760条结果,所以只需要计算前760个结果的相关性,就能满足要求。
由于所有匹配文件都已经具备了最基本的相关性(这些文件都包含所有查询关键词),搜索引擎会先筛选出1000个页面权重较高的一个文件,通过对权重的筛选初始化一个子集,再对这个子集中的页面进行相关性计算。
4、相关性计算
用权重选出初始子集之后,就是对子集中的页面计算关键词相关性的步骤了。计算相关性是排名过程中最重要的一步,影响相关性的主要因素包括如下几个方面:
① 关键词常用程度
经过分词后的多个关键词,对整个搜索字符串的意义贡献并不相同。越常用的词对搜索词的意义贡献越小,越不常用的词对搜索词的意义贡献越大。所以搜索引擎对搜索词串中的关键词并不是一视同仁地处理,而是根据常用程度进行加权。不常用的词加权系数高,常用词加权系数低,排名算法对不常用的词给予更多关注。
② 词频及密度
一般认为在没有关键词堆积的情况下,搜索词在页面中出现的次数多,密度越高,说明页面与搜索词越相关。当然这只是一个大致规律,实际情况未必如此,所以相关性计算还有其他因素。出现频率及密度只是因素的一部分,而且重要程度越来越低。
③ 关键词位置及形式
就像在索引部分中提到的,页面关键词出现的格式和位置都被记录在索引库中。关键词出现在比较重要的位置,如标题标签、黑体、H1等,说明页面与关键词越相关,这一部分就是页面SEO所要解决的。
④ 关键词距离
切分后的关键词完整匹配的出现,说明与搜索词最相关。比如搜索“减肥方法”时,页面上连续完整出现“减肥方法”四个字是最相关的。如果“减肥”和“方法”两个词没有连续匹配出现,出现的距离近一些,也被搜索引擎认为相关性稍微大一些。
⑤ 链接分析及页面权重
除了页面本身的因素,页面之间的链接和权重关系也影响关键词的相关性,其中最重要的是锚文字。页面有越多以搜索词为锚文字的导入链接,说明页面的相关性越强。链接分析还包括了链接源页面本身的内容主题、锚文字周围的文字等。
小结:以上狂人SEO详细分享了搜索引擎的工作原理,了解这些知识对于我们做百度网站收录有重要意义,比如标题要包含用户可能搜索的需求词,正文适量体现关键词或拆分词有助于判断内容与用户搜索词的相关性。

- Register
- Dropcatch
- Auction
- Buy It Now
- Cloud Products
- Other
-
Control Panel
- Account
- Finance
- Dropcatch
- Domain
- Buyer
- Seller
- Cloud Products Ticket System
-
0
- Register()
- Renew()
- Redeem()
- Transfer In()
- Buy It Now()
- Backorder()
- PUSH In()
- Offline Register()
- Cloud Products(0)
- Others(0)
- Website Building()
- Website Protection()
- VPS Hosting()
- SSL Certificates()
- Professional Email()
- Auth Code()
 You are able to view your cart after login, please login firstlyLogin Now
You are able to view your cart after login, please login firstlyLogin Now
There is no data in your cart~
You are able to view your cart after login, please login firstlyLogin Now
There is no data in your cart~
You are able to view your cart after login, please login firstlyLogin Now
There is no data in your cart~
Select allDelete -
Search history
Clear history









 supports the following regional currency settlement:
AlipayHK (Hong Kong, China): Supports HKD Settlement
TNG eWallet (Malaysia): Supports MYR Settlement
GCash Pay (Philippines): Supports PHP Settlement
DANA Pay (Indonesia): Supports IDR Settlement
Kakao Pay (South Korea): Supports KRW Settlement
TrueMoney (Thailand): Supports THB Settlement
Rabbit LINE Pay (Thailand): Supports THB Settlement")




